
VMware ESXi ortamlarında performans sorunlarını analiz etmek ve darboğazları tespit etmek için başvurulan en güçlü araç esxtop’tur. ESXi ile yerleşik olarak gelen, gerçek zamanlı ve ücretsiz bu komut satırı aracı, vCenter arayüzünün sunamadığı derinlikteki metrikleri milisaniye hassasiyetinde sağlar.
Production ortamlarındaki kritik performans sorunları; CPU contention (%RDY time), memory swapping, storage latency veya network packet drops gibi faktörler esxtop ile dakikalar içinde izole edilebilir. Özetle; vCenter size bir sanal makinenin “yavaş” olduğunu söylerken, esxtop bu yavaşlığın nedenini kanıtlarıyla ortaya koyar.
Bu kapsamlı rehberde, bir sistem yöneticisinin ihtiyaç duyacağı şu temel konuları detaylandırmaya çalışacağım:
- Çalışma Modları: Interactive, Batch ve Replay modlarının kullanım senaryoları.
- Derinlemesine Metrik Analizi: CPU, Memory, Disk ve Network panellerindeki kritik veriler.
- Sorun Giderme Metodolojisi: Threshold değerleri ve performans yorumlama teknikleri.
- Otomasyon: PowerCLI kullanarak esxtop verilerinin otomatikleştirilmesi.
- İzleme Stratejileri: Üretim ortamlarında esxtop ile sürdürülebilir izleme yöntemleri.
Not: Bu rehber vSphere 6.5 – 9.0 versiyonları için geçerlidir. Versiyon detayları için ESXi Build Numbers rehberini inceleyebilirsiniz.
ESXTOP: Sanallaştırma Dünyasının “Kara Kutusu” (2001 – 2026+)
esxtop, VMware’in kernel seviyesindeki (VMkernel) en derin verilerine erişim sağlayan en sadık aracıdır.
ESXTOP Versiyon Geçmişi
- 2001: Doğuş (ESX 2.0)
- 2008: Uzaktan Erişim Devrimi (vSphere 4.x – resxtop)
- 2015: Analiz ve Raporlama Çağı (vSphere 6.0)
- 2020: Proaktif İzleme (vSphere 7.0+)
- 2025 ve Ötesi: Değişmez Standart (vSphere 9.x+)
ESXTOP vs Diğer Monitoring Araçları
VMware ekosisteminde her aracın spesifik bir görevi vardır. Doğru aracı seçmek, sorunu çözme hızınızı belirler.
1. Latency ve Granülarite Farkları:
- ESXTOP: Gerçek zamanlı (varsayılan 2 saniye refresh), maksimum granülarite. Kernel seviyesinden doğrudan veri çeker.
- vCenter Performance: Gecikmeli veridir (~20 saniye delay), geçmişe dönük trendleri izlemek için optimize edilmiştir.
- Aria Operations: Stratejik veridir (~5 dakika delay), tahminleme ve kapasite planlama için kullanılır.
2. Root Cause Analiz
- vCenter UI görüntüsü: Sadece yüzeysel bilgi verir; örneğin: “%CPU Usage: 85%”
- ESXTOP görüntüsü: Sorunun kaynağını söyler; örneğin: “%USED: 85, %RDY: 23, %CSTP: 8, %SWPWT: 2”
3. Kullanım Senaryoları:
- Acil Sorun Giderme: → ESXTOP (Şu anda sistemi ne kilitliyor?)
- Trend Analizi & Raporlama: → vCenter Performance (Geçen hafta yük neden arttı?)
- Proaktif İzleme & Kapasite Yönetimi: → Aria Operations (Gelecek ay ek sunucu gerekecek mi?)
- Konfigürasyon Denetimi: → ESXCLI (Sistem ayarları standartlara uygun mu?)
Not: VMware Aria Operations, 2023 yılında vRealize Operations (vROps) ürününün yeniden adlandırılmış halidir. Detaylı bilgi için Aria Operations rehberini inceleyebilirsiniz.
Kurumsal ortamlarda bu araçlar birbirinin alternatifi değil, tamamlayıcısıdır. Ancak anlık müdahale ve kritik darboğaz analizlerinde esxtop kullanımı vazgeçilmezdir.
ESXTOP’un 3 Çalışma Modu
Esxtop’u üç farklı modda çalıştırabilirsiniz. Her birinin kendine özel kullanım senaryosu vardır.
1. Interactive Mode – Canlı İzleme
En yaygın kullanım modu, SSH üzerinden host’a bağlanıp esxtop komutunu çalıştırmaktır. Real-time ekran görüntülenir.
ssh root@esxi-prod-01.company.local
esxtop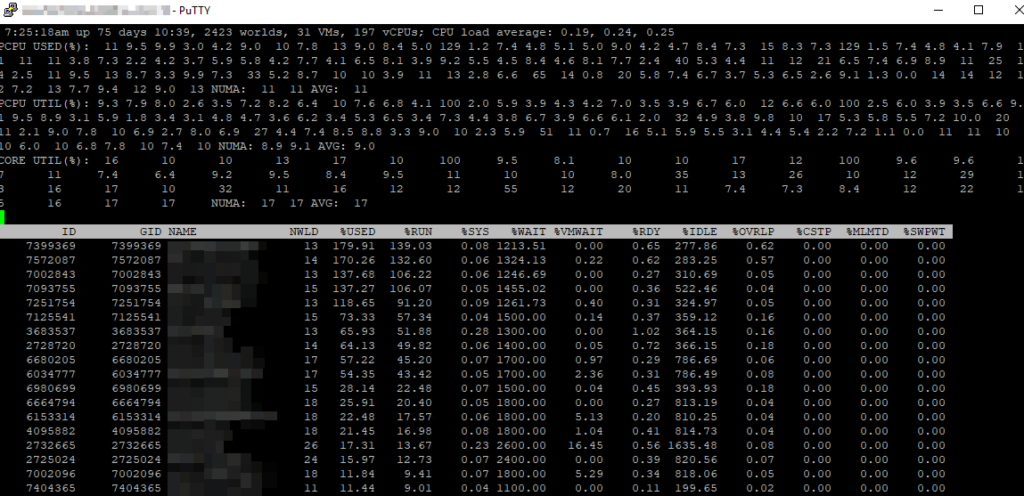
Ekran varsayılan olarak 2 saniyede bir yeniler (s tuşu ile değiştirilebilir). Klavye kısayollarıyla farklı görünümler (view) arasında geçiş yapılır:
- c → CPU view
- m → Memory view
- d → Disk adapter view
- u → Disk device view (LUN bazında)
- n → Network view
💡 Pro-Tip:
Hangi sütunların görüneceğini seçmek içinftuşunu, yaptığınız özelleştirmeleri kaydetmek için (bir sonraki açılışta aynı gelmesi için)Wtuşunu kullanarak yapılandırmayı.esxtop8rcdosyasına kaydedebilirsiniz.
2. Batch Mode – Veri Toplama (Logging)
Batch mode, esxtop’u CSV formatında dışa aktarmak için kullanılır ve ekrana çıktı vermez. Sadece dosyaya yazar. Uzun süreli analizler için idealdir.
esxtop -b -d 2 -n 100 > /vmfs/volumes/datastore1/esxtop_$(date +%Y%m%d_%H%M).csvParametreler:
-b: Batch mode aktivasyonu.-d 2: Her 2 saniyede bir örneklem.-n 100: 100 yineleme (Örn: 2sn x 100 = 200 saniye veri toplar).> file.csv: CSV’ye yaz
Kullanım Senaryosu: “Her gece 03:00’te yedekleme sırasında sistem yavaşlıyor” gibi vakalarda cron job ile otomatize edilir:
# /var/spool/cron/crontabs/root (Not: ESXi reboot sonrası bu dosya sıfırlanır, kalıcılık için /etc/rc.local.d/local.sh kullanılmalıdır)
0 3 * * * /bin/esxtop -b -d 60 -n 60 > /vmfs/volumes/monitoring-ds/esxtop-nightly-$(date +\%Y\%m\%d).csvKritik: Batch mode verisini asla local disk (/tmp, /scratch) üzerine yazmayın. ESXi ramdisk üzerinde çalıştığı için dolduğunda host’un yanıt vermemesine (PSOD riskine) neden olabilir. Mutlaka bir Datastore yolu gösterin.
3. Replay Mode – Geçmiş Analiz (Post-Mortem)
Replay mode, daha önce toplanmış vm-support paketi içindeki performans verilerini interaktif bir şekilde tekrar oynatır.
# Önce vm-support bundle toplayın
vm-support
# Sonra replay mode ile paketi açın
esxtop -R /tmp/esx-esxi-prod-01-2026-01-14.tgzBu mod genellikle Post-Mortem analizlerde kullanılır. Olay kapandıktan sonra, “Tam o kriz anında hangi VM’in IOPS değeri peak yapmıştı?” sorusuna saniye saniye yanıt bulmak için adeta bir zaman makinesi görevi görür. VMware Support mühendislerinin de Root Cause analiz raporu hazırlarken en çok başvurduğu yöntemlerden birisidir.
İlk ESXTOP Oturumunuz
esxtop aracını standart bir terminal arayüzü olarak değil, hypervisor katmanının “canlı röntgeni” olarak değerlendirmek gerekir. Donanım ve yazılım arasındaki etkileşimi milisaniye hassasiyetinde analiz etmek için ilk oturumunuzu şu adımlarla başlatabilirsiniz:
1. Hazırlık (Prerequisites)
Analize başlamadan önce aşağıdaki üç temel gereksinimin karşılandığından emin olun:
- SSH Servis Yapılandırması: ESXi host üzerinde SSH servisinin aktif olması gerekir.
- Yetkilendirme: Analiz, VMkernel istatistiklerine tam erişim gerektirdiği için
rootyetkilerine veyaESXAdminrolüne sahip bir hesapla oturum açılmalıdır. - Terminal: Veri akışının doğru görselleştirilmesi için UTF-8 destekli bir SSH istemcisi (PowerShell Core, iTerm2 veya PuTTY) tercih edilmelidir.
2. İlk Bağlantı ve Çalıştırma
SSH üzerinden güvenli bağlantı kurulup komut yürütüldüğü andan itibaren, VMkernel seviyesindeki canlı veri akışı başlar. Terminal üzerinden erişim süreci şu şekildedir:
# ESXi host'a root yetkileriyle erişim
ssh root@<ESXi-IP-veya-FQDN>
# SSH shell açıldıktan sonra aracı başlatın
[root@esxi-host:~] esxtop- Uygulama ilk açıldığında varsayılan olarak CPU View paneli yüklenir. Eğer terminal ekranınızda karakter kayması yaşanıyorsa, yazı tipi boyutunu küçültmek veya pencereyi tam ekran yapmak, tabloların doğru hizalanmasını sağlayacaktır.
3. Ekranın Anatomisi
esxtop arayüzü, sistemin genel sağlığını analiz etmenizi sağlayan iki ana katmandan oluşur:
- Üst Katman (Global Statistics): Host’un uptime süresini, toplam Load Average değerleri ve fiziksel işlemci (PCPU) bazlı anlık kullanım özetlerini sunar. Burası, genel bir darboğaz olup olmadığını saniyeler içinde anlamanızı sağlar.
- Alt Katman (World/Object Details): Sanal makinelerin ve kernel süreçlerinin detaylı listesidir. GID (Group ID) ve NAME sütunları, sorunlu objeyi hedeflemek için temel referans noktalarınızdır.
4. Operasyonel Kontrol: Klavye Kısayolları (Cheat Sheet)
esxtop tamamen klavye üzerinden yönetilen interaktif bir araçtır. Analiz sırasında hız kazanmak için kısayolları şu şekilde gruplandırabiliriz:
| Kategori | Tuş | Fonksiyon |
| Görünüm Değiştir | c | CPU: İşlemci kuyruğu ve yük analizi. |
m | Memory: RAM sıkışması ve swapping takibi. | |
u | Disk Device: LUN bazlı gecikme (latency) tespiti. | |
n | Network: Port trafiği ve paket kayıpları. | |
| Ekranı Yönet | f | Fields: Hangi sütunlar görünsün/gizlensin? |
s | Interval: Yenileme hızı (Varsayılan 2sn). | |
W | Save: Yaptığınız ayarları .esxtop8rc dosyasına kaydeder. | |
| Navigasyon | e | Expand: Seçili VM’in içindeki world’leri (alt süreçleri) açar. |
l | Limit: Sadece spesifik bir GID numarasına odaklanır. | |
q | Quit: Güvenli çıkış. |
Analiz sırasında ekran karmaşasını önlemek için f tuşuna basarak ihtiyacınız olmayan tüm sütunları devredışı bırakabilirsiniz. Örneğin bir CPU analizi için şu sütun setini açık bırakıp W ile kaydedebilirsiniz:
- %USED: Gerçek tüketim.
- %RDY: Kaynak bekleme süresi.
- %CSTP: Çekirdekler arası senkronizasyon kaybı.
- %MLMTD: Konfigürasyon kaynaklı kısıtlama.
Bu sadeleştirilmiş görünüm, kalabalık hostlarda “gürültüyü” azaltarak doğrudan root cause’a odaklanmanızı sağlar.
CPU Performans Analizi: Deep Dive
CPU görünümü (c), ESXTOP ekosisteminin en kritik panelidir. Bu ekranda temel amacımız sadece kullanım yüzdesini ölçmek değil, sanallaştırma katmanındaki “CPU Scheduling” verimliliğini analiz etmektir. Bir VM’in yavaşlığı genellikle CPU’nun yetersizliğinden değil, CPU’ya erişim sırasındaki bekleme sürelerinden kaynaklanır.
1. Host Katmanı: Global İstatistikler
Panelin üst kısmındaki metrikler, fiziksel donanımın genel yük karakteristiğini özetler:
- PCPU USED vs. UTIL:
Eğer UTIL değeri USED değerinden yüksekse, donanım katmanında power management politikaları nedeniyle frekans kısıtlaması yaşanıyor olabilir. Performans odaklı sistemlerde bu değerlerin birbirine yakın olması beklenir.
- Load Average: 1, 5 ve 15 dakikalık periyotlarda CPU kuyruğunda bekleyen süreçlerin ortalamasıdır.
2. Kritik Metrikler ve Teşhis Matrisi
Aşağıdaki metrikler, sanal makinelerin performansını doğrudan etkileyen kernel seviyesindeki gecikmeleri ifade eder. Bu değerlerin doğru yorumlanması, sorunun kaynağını (donanım vs. konfigürasyon) netleştirir.
| Metrik | Teknik Tanım | Normal | Risk | Aksiyon Planı |
| %RDY | Ready: vCPU çalışmaya hazır ancak VMkernel fiziksel çekirdek tahsis edemiyor. | < %5 | > %10 | vCPU sayısını azaltın; Host üzerindeki VM yoğunluğunu dengeleyin. |
| %CSTP | Co-Stop: vSMP (çoklu vCPU) makinelerde çekirdeklerin paralel çalışma senkronizasyonu bozulmuş. | < %3 | > %3 | VM’e gereğinden fazla vCPU verilmiş olabilir; vCPU sayısını düşürün. |
| %MLMTD | Max Limited: Sanal makine üzerindeki CPU Limit konfigürasyonu nedeniyle vCPU durdurulmuş. | %0 | > %0 | Resource Settings altındaki “Limit” kısıtlamasını kaldırın. |
| %SWPWT | Swap Wait: CPU, diske swap edilmiş olan RAM içeriğinin okunmasını bekliyor. | %0 | > %1 | Sorun CPU değil, Memory’dir; Host RAM kapasitesini kontrol edin. |
Altın Kural: %RDY < %5 olmalıdır. Eğer bir VM’de bu değer %10’u geçiyorsa, uygulama içinde “donma” (stuttering) hissi başlar.
3. Vaka Analizi: SQL Server Performans Paradoksu
Durum: Kritik bir SQL Server VM’i %89 CPU kullanımıyla çalışıyor. Sanal makinenin kaynak tüketimi normal görünse de uygulama sorguları zaman aşımına uğruyor.
ESXTOP Verisi:
GID NAME %USED %RUN %RDY %CSTP vCPU
12345 SQL-PROD-01 89 91 23 8 8Root Cause
- %RDY = %23: Bu metrik, sanal makinenin çalışma döngüsünün neredeyse dörtte birini fiziksel işlemci sırası bekleyerek “atıl” geçirdiğini kanıtlar. Bu kadar yüksek bir bekleme süresi, SQL Server gibi milisaniyelik gecikmelere hassas uygulamalarda felç edici bir etkidir.
- %CSTP = %8: VM’e atanan 8 vCPU, kernel seviyesinde ciddi bir senkronizasyon maliyeti yaratmaktadır.
Çözüm Stratejisi: “Less is More”, Enterprise ortamlarda yapılan en büyük hata, hızı artırmak için sürekli vCPU eklemektir. Oysa sanallaştırmada verimlilik, işlemci sayısından ziyade işlemcinin “bulunabilirliği” ile ölçülür.
- Aksiyon: Sanal makinenin vCPU sayısı 8’den 4’e düşürülerek Right-Sizing yapılmalıdır.
- Sonuç: ESXi scheduler, 4 adet boş fiziksel çekirdeği çok daha hızlı ve sık bulabildiği için
%RDYdeğeri %2’ye geriler. VM, daha az işlemci çekirdeğiyle aslında daha fazla “iş” üretmeye başlar.
4. Co-Stop Time (%CSTP) Problemi
%CSTP metriği, çok çekirdekli sanal makinelerde görülen mimari bir darboğazdır. ESXi Scheduler, modern sürümlerde “Relaxed Co-Scheduling” kullansa da, bir VM’in vCPU’ları arasındaki zaman farkı çok açıldığında performansı korumak için süreci durdurur.
Örnek:
GID NAME %CSTP vCPU
67890 WEB-APP-03 12 4- Teknik Analiz:
%CSTP = %12değeri, sanal makinenin çekirdekleri arasındaki koordinasyonun koptuğunu gösterir. Uygulama, CPU üzerinde işlem yapmaktan ziyade çekirdeklerin birbirini beklemesini koordine etmekle meşguldür.
Nedenleri ve Çözümü
- Orantısız vCPU Ataması: Uygulama tek çekirdek (single-thread) ağırlıklı çalışıyor olmasına rağmen 4 vCPU tahsis edilmesi, hypervisor üzerinde gereksiz bir senkronizasyon yükü bindirir.
- Host Seviyesinde Over-commitment: Host üzerindeki toplam vCPU / pCPU oranı 4:1 eşiğini aştığında, scheduler uygun boşluk bulamaz ve
%CSTPsüreleri artar. - NUMA Misalignment: VM belleğinin farklı bir NUMA node da olması, işlemciler arası iletişimi (inter-processor interrupts) yavaşlatarak senkronizasyonu zorlaştırır.
Kurumsal mimarilerde çoğu web ve uygulama sunucusu, 4 vCPU yerine optimize edilmiş 2 vCPU ile çok daha düşük gecikme ve daha yüksek stabilite ile çalışmaktadır. Performans sorununda ilk adım kaynak artırmak değil, mevcut kaynağın verimliliğini (%RDY ve %CSTP üzerinden) sorgulamak olmalıdır.
Memory Performans Analizi
İşlemciden sonra sanallaştırma performansını belirleyen en kritik bileşen bellektir. m tuşuna basarak ulaşılan “Memory View” paneli, ESXi kernel’ının kaynak yönetim stratejilerini ve bu stratejilerin sanal makineler üzerindeki etkisini milisaniye hassasiyetinde sunar.
1. Host Memory Envanteri (Global Stats)
Panelin üst kısmındaki metrikler, fiziksel kaynakların operasyonel sınırlarını belirler:
- PMEM /MB: Host üzerindeki toplam fiziksel RAM kapasitesidir.
freedeğeri, toplam kapasitenin %5’inin altına düşerse, ESXi host “Hard State” moduna geçer ve en agresif bellek geri kazanım yöntemlerini devreye sokar. - VMKMEM /MB: ESXi kernel’ının kendi süreçleri için ayırdığı bellektir. Bu değerin kontrolsüz yükselmesi, kernel seviyesinde bir leak işareti olabilir.
2. Kritik Teşhis Matrisi: Memory Sağlık Göstergeleri
| Metrik | Teknik Tanım | Normal Eşik | Alarm / Kritik | Aksiyon Planı |
| GRANT | Host’un VM’e tahsis ettiği net fiziksel RAM. | MEMSZ’ye yakın | GRANT << MEMSZ | Host üzerinde ağır bellek baskısı var; kaynak dağılımını inceleyin. |
| MCTLSZ | Ballooning: Sürücü aracılığıyla geri alınan bellek. | 0 MB | > 1 GB | Host RAM talep ediyor; VM içindeki yükleri optimize edin. |
| SWCUR | Swapping: Diskteki aktif swap miktarı. | 0 MB | > 0 MB | Kritik: Bellek diskten okunuyor. Acil kapasite artırımı planlayın. |
| %SWPWT | CPU’nun diskteki swap verisini beklediği süre. | %0 | > %1 | Performans kaybı kesinleşmiş durumda; gecikme saniye bazındadır. |
Kritik Kural: “Swap = Performansın Ölümü” ESXi dünyasında SWCUR > 0 değeri, performansın bittiği noktadır. Bellek erişimi disk katmanına (SSD/NVMe olsa dahi) düştüğü an, gecikme süreleri milisaniyelerden saniyelere çıkar.
3. Memory Geri Kazanım Hiyerarşisi (Reclamation Steps)
ESXi, bellek sıkıştığında kaynakları kurtarmak için sırasıyla şu dört yöntemi kullanır. Bu hiyerarşiyi bilmek, krizin derinliğini anlamanızı sağlar:
- TPS (Transparent Page Sharing): Bellekteki yinelenen veri bloklarını tekilleştirir. İşlemciye maliyeti düşüktür, uygulama bunu hissetmez.
- Ballooning (MCTLSZ): VM içindeki VMware Tools sürücüsü (vmmemctl) üzerinden RAM talep edilir. Guest OS, hangi sayfanın önemsiz olduğunu bildiği için bu “kontrollü” bir yavaşlamadır.
- Compression (Sıkıştırma): Sayfalar diske yazılmadan önce RAM içinde sıkıştırılır. CPU’ya ek yük biner ancak diskten okumaya göre çok daha hızlıdır.
- Swapping (SWCUR): Son çare ve felaket senaryosu. ESXi, Guest OS’un fikrini sormadan sayfaları
.vswpdosyasına yazar. Latency 10.000 kat artar.
4. Vaka Analizi: Veritabanı (DB-SERVER) Yanıt Vermeme Sorunu
Senaryo: Kritik bir SQL sunucusunda sorgu süreleri 10 saniyeden 2 dakikaya çıktı. vCenter grafikleri CPU kullanımının normal olduğunu söylüyor.
GID NAME MEMSZ GRANT SWCUR %SWPWT
22222 DB-SERVER 32768 24576 8192 18Teknik Teşhis (Diagnosis)
- SWCUR = 8 GB: Sistemin 8 GB belleği fiziksel RAM’den atılıp diske taşınmış. RAM artık mekanik veya SSD diskten okunmaya çalışılıyor.
- %SWPWT = %18: İşlemci zamanının %18’i sadece diskten RAM sayfasının gelmesini beklemekle (I/O Wait) boşa geçiyor.
- Kök Neden: Host üzerindeki Overcommitment oranı 1.2’ye çıkmış; ESXi “Hard State” moduna geçerek zorla swapping başlatmış.
Acil Müdahale ve Kalıcı Çözüm:
- Hızlı Müdahale: VM’e “Memory Reservation” tanımlayın. Bu, ESXi’ı o belleği fiziksel RAM’de tutmaya zorlar. Boştaki VM’leri kapatın veya migrate edin.
- Kapasite Planlama: Üretim ortamlarında Overcommit oranını 0.80 altında tutun.
- Proaktif İzleme:
SWCUR > 100MBolduğu an P1 (Kritik) seviyeli alarm kurgulayın.
Veritabanı gibi “bellek canavarı” uygulamalar Swapping’e karşı toleranssızdır. Bu tip VM’ler için “Reserve all guest memory” seçeneğini işaretlemek, operasyonel bir sigortadır.
Storage Performans Analizi: Latency’nin Anatomisi
Depolama birimlerindeki yavaşlık, uygulama katmanından kullanıcı deneyimine kadar tüm sistemi felç edebilir. esxtop üzerinde depolama karmaşasını çözmek için üç temel görünüm kullanılır:
- d (Adapter): HBA (FC/iSCSI) bazlı fiziksel darboğazları izler.
- u (Device): LUN bazlı analizde en çok kullanılan ekrandır; donanım seviyesindeki gecikmeyi gösterir.
- v (Disk VM): Hangi sanal makinenin “Noisy Neighbor” (gürültücü komşu) olduğunu tespit etmenizi sağlar.
1. Altın Formül: GAVG = DAVG + KAVG
Gecikmenin (latency) nerede oluştuğunu saniyeler içinde anlamak için şu denklem referans alınmalıdır:
| Metrik | Teknik Tanım | Normal | Kritik Eşik | Sorun Nerede? |
| DAVG | Device Latency: I/O paketinin HBA’dan çıkıp Storage Array’e gidip gelme süresi. | < 10 ms | > 20 ms | Storage Array, SAN Switch veya fiziksel kablolama. |
| KAVG | Kernel Latency: I/O’nun ESXi kernel katmanındaki kuyrukta bekleme süresi. | < 2 ms | > 5 ms | ESXi Host (HBA Queue Depth limitlerine ulaşılmış). |
| GAVG | Guest Latency: İşletim sisteminin hissettiği toplam gecikme süresi. | < 15 ms | > 30 ms | Toplam sistem gecikmesi. |
Eğer GAVG değeri 5000 ms üzerine çıkarsa, sistem “SCSI Command Abort“ üretir. Bu durum disklerin geçici olarak kilitlenmesi ve veritabanı servislerinin çökmesi ile sonuçlanır.
2. Vaka Analizi: Storage Latency Spike ve Noisy Neighbor
Senaryo: İzleme sisteminden “LUN-01 Latency > 50ms” alarmı geldi. Kritik SQL sunucuları sorgu işleyemiyor.
Adım 1: LUN Analizi (u tuşu)
DEVICE CMDS/s DAVG KAVG GAVG READS/s WRITES/s
naa:60...01 3200 45 2 47 150 3050DAVG (45ms) çok yüksek, ancak KAVG normal. Sorun storage tarafında ancak tetikleyici bir “I/O canavarı” var; çünkü CMDS/s (IOPS) normalin çok üzerinde.
Adım 2: Suçlunun Tespiti (v tuşu)
Kritik soru: Bu trafiği hangi VM yaratıyor?
GID NAME CMDS/s LAT/rd LAT/wr
98765 BACKUP-SERVER 2950 52 48
11111 SQL-PROD-01 180 9 8Kök Neden: BACKUP-SERVER toplam I/O trafiğinin %90’ını tek başına üreterek tüm LUN’un bant genişliğini domine etmiş.
Çözüm ve Aksiyon Planı
- Acil Müdahale: Çakışan yedekleme (backup) süreci durduruldu. 5 dakika içinde
DAVG8ms seviyesine geriledi. - İzolasyon (Segmentation): Yedekleme trafiği, prodüksiyon datastore’larından ayrılarak dedike (SATA/NL-SAS) bir disk havuzuna taşındı.
- SIOC (Storage I/O Control): Datastore seviyesinde SIOC aktif edilerek, tek bir VM’in tüm LUN bandını domine etmesi donanımsal olarak engellendi.
- IOPS Limitleme: Kritik olmayan iş yüklerine (Backup, Dev/Test) vSphere seviyesinde IOPS limitleri tanımlandı.
3. Storage Troubleshooting Decision Tree
Disk yavaşlığı raporlandığında panik yapmadan şu algoritmik sırayı izleyin:
- GAVG’yi Kontrol Et: > 25ms ise sorun gerçektir.
- DAVG vs. KAVG Kıyaslaması Yap:
- VM View (
v) Paneline Geç: En yüksekCMDS/s(IOPS) veMB/s(Throughput) üreten VM’i bulun. - Müdahale Et: Suçlu VM’i farklı bir host/datastore’a migrate edin veya I/O limitleri koyun.
Sonuç: Bankacılık veya yüksek işlem hacimli ortamlarda tek bir VM’in yanlış yapılandırılmış yedekleme görevi tüm altyapıyı durdurabilir. esxtop ile bu “gürültücü” objeleri saniyeler içinde ayıklamak, operasyonel sürekliliğin temelidir.
Network Performans İzleme: Paket Kayıplarının Tespiti
Ağ görünümü (n), CPU veya Disk panelleri kadar sık ziyaret edilmese de, vSphere altyapısındaki gizli performans katillerini (paket kayıpları ve bant genişliği limitleri) kernel seviyesinde teşhis etmek için benzersizdir. Bu panelde hem fiziksel uplink’ler (vmnic) hem de sanal portlar üzerindeki trafik anlık olarak izlenir.
1. Network Paneli Metrik Anatomisi
Sağlıklı bir kurumsal ağ mimarisinde veri paketleri kayıpsız iletilmelidir. esxtop üzerindeki şu iki metrik, ağ sağlığının temel göstergesidir:
- MbTX/s – MbRX/s: Saniye başına iletilen (Transmit) ve alınan (Receive) Megabit miktarı.
- %DRPTX – %DRPRX: Gönderilen ve alınan paketlerdeki düşme (drop) yüzdesi.
| Metrik | Teknik Tanım | Normal Eşik | Kritik Eşik |
| %DRPTX | Host’tan dışarı çıkan paketlerdeki kayıp oranı. | %0.00 | > %0.00 |
| %DRPRX | Host’a gelen paketlerdeki kayıp oranı. | %0.00 | > %0.00 |
Kurumsal ağlarda %0.01’lik bir paket kaybı dahi veritabanı replikasyonlarında tutarsızlıklara ve yüksek işlem hacimli (high-throughput) servislerde ciddi gecikmelere yol açar.
2. Dropped Packets: Performansın Gizli Katili
Senaryo: İzleme sırasında vmnic1 üzerinde %DRPTX = 0.08 değeri tespit edildi. İlk bakışta küçük görünen bu rakam, ağ kartının (NIC) buffer kapasitesinin dolduğunu ve trafiği kaldıramadığını gösteren bir “imdat” çağrısıdır.
Root Cause Analiz
- NIC Overload: 1Gbps’lik bir fiziksel kart üzerinden sürekli 900Mbps+ trafik geçiyorsa, buffer dolar ve kernel paketleri düşürmeye başlar.
- Legacy Adaptör Kullanımı: Sanal makine içinde modern
VMXNET3yerine eski nesile1000veyae1000eadaptörlerinin kullanılması. - Hatalı Load Balancing: vSwitch üzerindeki yük dengeleme politikalarının (Örn: Route based on IP hash) fiziksel switch konfigürasyonuyla (LACP/EtherChannel) uyumsuz olması.
- Sürücü/Firmware Uyuşmazlığı: Fiziksel ağ kartı sürücüsünün ESXi sürümüyle uyumsuzluğu nedeniyle kernel seviyesinde yaşanan “interrupt” hataları.
3. Çözüm ve Optimizasyon Yol Haritası
Paket kaybı tespit edildiğinde şu adımlar izlenmelidir:
- Trafik Dağıtımı: Eğer bir uplink kapasitesine çok yakınsa, trafiği diğer
vmnic‘lere dengeli dağıtmak için “Route based on physical NIC load” (LBT) politikasına geçiş yapın. - Adaptör Modernizasyonu: Tüm kritik sanal makinelerde ağ adaptör tipini VMXNET3 olarak güncelleyin. VMXNET3, paravirtualized yapısı sayesinde CPU yükünü azaltır ve “Offload” özellikleriyle paket kaybı riskini minimize eder.
- Donanım Ölçekleme: Modern veri merkezlerinde 1Gbps artık “darboğaz” kabul edilmektedir. Özellikle vMotion ve Storage trafiğinin geçtiği hatlarda 10Gbps, 25Gbps veya 100Gbps mimarisine geçiş planlayın.
4. Profesyonel Analiz İpucu: Interrupt Yönetimi
Eğer ağ trafiği yüksek olduğu halde CPU panelinde %iterm (interrupt time) değerleri yükseliyorsa, ağ trafiği fiziksel işlemciyi aşırı meşgul ediyor demektir. Bu durumda RSS (Receive Side Scaling) yapılandırmasını kontrol ederek ağ yükünün tüm CPU çekirdeklerine eşit dağıtıldığından emin olun.
esxtopağ paneli, vCenter’ın genelleştirilmiş trafik grafiklerinin ötesine geçerek, ağdaki “sessiz” kayıpları görünür kılar.DRPsütunlarını her zaman sıfırda tutmak, stabil bir sanallaştırma altyapısının olmazsa olmazıdır.
İleri Seviye: Batch Mode ve Performans Otomasyonu
İnteraktif mod anlık teşhisler için rakipsizdir; ancak “Dün gece saat 03:00’te yedekleme sırasında ne oldu?” sorusuna yanıt vermek veya uzun vadeli performans trendlerini izlemek için Batch Mode kullanımı zorunludur. Batch mode, esxtop verilerini terminale basmak yerine, analiz edilebilir bir CSV formatında diske yazar.
1. Batch Mode Mekanizması ve Parametre Yönetimi
Veri toplama sürecini başlatmak için kullanılan temel komut şöyledir:
esxtop -b -d 5 -n 720 > /vmfs/volumes/DATASTORE_PATH/esxtop-output.csv- -b (Batch): İnteraktif arayüzü kapatır ve veri aktarım modunu açar.
- -d 5 (Delay): Her 5 saniyede bir örnekle alır.
- -n 720 (Number): Toplam 720 döngü yapar (Bu örnekte: 5sn x 720 = 1 saatlik kesintisiz veri).
> esxtop-output.csv: Çıktıyı belirlenen yola yazar.
Kritik Güvenlik Uyarısı: Çıktı dosyasını asla
/tmpveya/vargibi lokal dizinlere yönlendirmeyin. ESXi ramdisk doluluğu, host’un yanıt vermeyi kesmesine veya Purple Screen of Death oluşmasına neden olabilir. Her zaman merkezi ve yeterli alanı olan bir VMFS Datastore yolu kullanın.
2. Kurumsal İzleme: 7/24 Otomatik Veri Toplama
Kronik ve rastgele zamanlarda ortaya çıkan performans darboğazlarını yakalamak için ESXi üzerinde planlanmış görevler (Cron Job) kurgulanmalıdır. Aşağıdaki script yapısı, verileri düzenli toplarken eski logları otomatik temizleyerek depolama alanını korur.
Bash Script: esxtop-collector.sh
#!/bin/bash
# Merkezi İzleme Dizini
DATASTORE_PATH="/vmfs/volumes/monitoring-ds/perf_logs"
TIMESTAMP=$(date +%Y%m%d_%H%M)
# Saatlik bazda 5'er dakikalık detaylı örneklem (10sn aralıklarla)
/bin/esxtop -b -d 10 -n 30 > $DATASTORE_PATH/esxtop-$TIMESTAMP.csv
# 30 günden eski verilerin otomatik rotasyonu
find $DATASTORE_PATH -name "esxtop-*.csv" -mtime +30 -deleteZamanlama (Crontab): Bu scripti /var/spool/cron/crontabs/root dosyasına ekleyerek her saat başı otomatik çalışmasını sağlayabilirsiniz.
3. Büyük Ölçekli Otomasyon: PowerCLI ve SSH Entegrasyonu
Onlarca hostun bulunduğu bir Cluster içerisinde manuel SSH bağlantısı kurmak operasyonel bir yüktür. Aşağıdaki PowerCLI betiği, tüm cluster üyelerine aynı anda bağlanarak arka planda (nohup) veri toplama işlemini başlatır.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# vSphere Cluster-Wide esxtop Automation $clusterName = "Production-Cluster" $remotePath = "/vmfs/volumes/shared-ds/logs" Connect-VIServer "vcenter.domain.local" $hosts = Get-Cluster $clusterName | Get-VMHost foreach ($vmhost in $hosts) { $ssh = New-SSHSession -ComputerName $vmhost.Name -Credential (Get-Credential) -AcceptKey if ($ssh.Connected) { # nohup ile oturum kapansa bile veri toplama devam eder $cmd = "nohup esxtop -b -d 30 -n 120 > $remotePath/$($vmhost.Name)-perf.csv 2>&1 &" Invoke-SSHCommand -SessionId $ssh.SessionId -Command $cmd Remove-SSHSession -SessionId $ssh.SessionId Write-Host "Monitoring started on: $($vmhost.Name)" -ForegroundColor Cyan } } |
4. CSV Verilerinin Analizi ve Görselleştirme
Toplanan binlerce satırlık veriyi anlamlandırmak için şu metodolojiler izlenmelidir:
- VisualEsxtop & ESXPLOT: VMware tarafından sunulan bu araçlar, CSV çıktılarını doğrudan grafiklere dönüştürerek
%RDYveyaGAVGsıçramalarını görsel olarak görmenizi sağlar. - Excel Pivot Tablo Analizi:
- Korelasyon Analizi: Sorun anında CPU
%RDYartarken aynı anda StorageGAVGdeğerinin de artıp artmadığını kontrol edin. Bu, sorunun işlemci yetersizliği mi yoksa I/O beklemesi mi olduğunu netleştirir.
Neden Bu Yaklaşım?
- Ölçeklenebilirlik: Tek bir host yerine tüm veri merkezini izlemenizi sağlar.
- Kanıt Temelli Teşhis: Uygulama sahiplerine “sunucu yavaştı” demek yerine, “Dün gece 02:15’te depolama gecikmesi 40ms’ye çıktığı için uygulama etkilendi” şeklinde somut veri sunmanızı sağlar.
- Proaktif Yaklaşım: Sorunlar oluşmadan önce trendleri (Örneğin her hafta artan bellek şişmesi/ballooning) fark etmenize olanak tanır.
5. RCA Süreçleri ve Teknik Raporlama Standartları
Performans sorunlarını çözmek kadar, bu sorunları yönetime veya uygulama sahiplerine profesyonel bir dille raporlamak da önemlidir. esxtop verileri (özellikle Batch Mode çıktıları), Root Cause Analiz raporlarının temel taşıdır.
“Sistem dün gece yavaştı” gibi muğlak ifadeler yerine; “03:15 periyodunda alınan Batch Mode verilerine göre, CPU %RDY değerinin %22’ye çıktığı ve aynı anda depolama katmanında DAVG değerinin 45ms olduğu ekteki grafiklerle kanıtlanmıştır” demek, mühendislik kalitenizi ve analitik yaklaşımınızı ortaya koyar.
6. Threshold Reference Card: Hızlı Başvuru Rehberi
Performans analizinde metriklerin sadece isimlerini bilmek yeterli değildir; hangi değerin “normal”, hangisinin “felaket” olduğunu saniyeler içinde ayırt etmeniz gerekir. Aşağıdaki tabloyu, kriz anlarında hızlıca göz atabileceğiniz bir “Başvuru Kartı” olarak kullanabilirsiniz.
| Kategori | Metrik | Sağlıklı (Normal) | Riskli (İzleme) | Kritik (Acil Müdahale) |
| CPU | %RDY | < %5 | %5 – %10 | > %10 (İşlemci Kuyruğu) |
| %CSTP | < %3 | %3 – %5 | > %5 (Over-provisioning) | |
| %MLMTD | %0 | – | > %0 (CPU Limiti Mevcut) | |
| Memory | MCTLSZ | 0 MB | 0 – 500 MB | > 1000 MB (Ağır Ballooning) |
| SWCUR | 0 MB | 1 – 50 MB | > 100 MB (SWAP – Felaket!) | |
| %SWPWT | %0 | – | > %1 (Disk Bekleme Süresi) | |
| Overcommit | < 0.50 | 0.50 – 0.80 | > 0.80 (Kaynak Sınırda) | |
| Storage | DAVG | < 10 ms | 10 – 20 ms | > 20 ms (Storage/SAN Hatası) |
| KAVG | < 2 ms | 2 – 5 ms | > 5 ms (Host Kuyruk Hatası) | |
| GAVG | < 15 ms | 15 – 30 ms | > 5000 ms (I/O TIMEOUT!) | |
| Network | %DRP TX/RX | %0.00 | – | > %0.01 (Paket Kaybı) |
Referans: Bu değerler, VMware’in resmi Performance Best Practices for vSphere dökümantasyonu temel alınarak yazılmıştır.
7. Saha Notları: Profesyonel İpuçları
Bu ipuçları, esxtop kullanımını standart bir izleme işleminden, ileri seviye bir adli analiz (forensics) sürecine dönüştürür.
7.1. Özel Görünümleri (Custom View) Kalıcı Hale Getirin
Her oturumda sütunları baştan düzenlemek zaman kaybıdır. İdeal analiz ekranınızı bir kez yapılandırıp kalıcı hale getirin:
file sütunları seçin,oile sıralamayı belirleyin.W(büyük harf) tuşuna basarak yapılandırmayı kaydedin.- Yapılandırma ESXi üzerinde
~/.esxtop8rcdosyasına yazılır ve her açılışta otomatik olarak yüklenir.
7.2. Gürültüyü Filtreleyin
Ekranda onlarca VM varken sadece hedeflediğiniz makineye odaklanmak için l (limit) tuşunu kullanın:
ltuşuna basın ve VM’in GID (Group ID) numarasını girin.- Bu işlem, diğer tüm süreçleri gizleyerek sadece ilgili nesnenin metriklerini milisaniye hassasiyetinde izlemenizi sağlar.
7.3. Terminal Uyumluluğu (macOS/Linux)
Özellikle macOS üzerinden SSH ile bağlandığınızda karakter kaymaları veya tablo bozulmaları yaşanabilir. Bağlanmadan önce terminal tipini standardize etmek bu sorunu çözer:
export TERM=xterm
ssh root@esxi-host7.4. Metrik Korelasyonu: esxtop + tmux
CPU panelindeki bir sorunun Memory veya Disk katmanıyla ilişkisini görmek için tmux kullanarak ekranı bölün. Bir panelde CPU (c), diğerinde Memory (m), bir diğerinde ise Disk (u) açık olduğunda, darboğazın “zıpladığı” katmanı anında yakalayabilirsiniz.
7.5. Baseline (Referans) Oluşturmanın Gücü
Performans sorunlarını anlamlandırmanın en iyi yolu, sistemin “sağlıklı” halini bilmektir:
- Normal Zaman: Haftalık
batch modeçıktıları alarak sistemin stabil halini (Baseline) arşivleyin. - Olay Anı: Kriz anındaki veriyi baseline ile karşılaştırın. Aradaki fark, sorunun başladığı katmanı size saniyeler içinde gösterecektir.
8. Çapraz Kontrol: esxtop vs. Guest OS
Analizin en kritik aşaması, hypervisor verilerini Sanal Makine (Guest OS) içindeki metriklerle doğrulamaktır. Bu korelasyon, sorunun gerçek katmanını netleştirir:
| Senaryo | ESXTOP Durumu | Guest OS (Windows/Linux) | Teknik Teşhis |
| A | %RDY = %15 | CPU Kullanımı Düşük | Problem Hypervisor katmanında; CPU Contention var. |
| B | %USED = %90 | Uygulama CPU %100 | Problem Uygulama katmanında; hatalı kod veya sonsuz döngü. |
| C | SWCUR > 0 | Bellek Kullanımı Stabil | Problem Host katmanında; Host RAM bittiği için VM’i zorla swap yapıyor. |
Sonuç: Veriyle Konuşmak
esxtop, bir sanallaştırma yöneticisinin elindeki en dürüst araçtır. vCenter grafiklerinin arkasına saklanan mikro-darboğazları görünür kılar. Bu rehber boyunca ele aldığımız metrikler, eşik değerler ve otomasyon yöntemleri; sizi “deneme-yanılma” yönteminden kurtarıp, veriye dayalı mühendislik seviyesine taşıyacaktır.
Şu 4 kuralı bilmek, karşılaşılan performans sorunlarının %80’ini teşhis etmek için yeterlidir:
- %RDY > 10 = İşlemci Felci
- GAVG > 20 = Depolama Darboğazı
- SWCUR > 0 = Bellek İflası
- %DRP > 0 = Ağ Paket Kaybı
Neden ESXTOP Kullanmalısınız?
Profesyonel bir sistem mühendisinin alet çantasında esxtop‘un bulunması için 5 kritik neden:
- Doğrudan Kernel Verisine Erişim: Başka hiçbir araç, VMkernel seviyesindeki veriyi bu kadar düşük overhead ve yüksek doğrulukla sunamaz. Katmanlar arasında kaybolmadan doğrudan kaynağa bakarsınız.
- Bağımsız ve Ücretsiz Güç: Lisans gerektirmez, ek kurulum istemez. vCenter’ın ulaşılamaz olduğu veya donduğu kriz anlarında bile her ESXi host’un içerisinde sizi bekleyen bir “acil durum” aracıdır.
- Gizli Darboğazları Keşfetme: Standart dashboard’ların “yüzde” olarak özetleyip geçtiği metriklerin arkasındaki gerçekleri görürsünüz. CPU Ready (%RDY), Co-Stop (%CSTP) veya Kernel Latency gibi “hayat memat meselesi” detaylar sadece burada netleşir.
- Kriz Anında Hızlı İzolasyon: Gece yarısı gelen kritik bir performans çağrısında, onlarca grafik arasında kaybolmak yerine “Noisy Neighbor” (gürültücü komşu) objeleri saniyeler içinde tespit edebilirsiniz.
- Teknik Fark Yaratan Yetkinlik:
esxtopkullanabilmek, bir VMware yöneticisini operatör seviyesinden uzman seviyesine çıkaran “imza” bir yetkinliktir. Bu aracı kullanmak, altyapının sadece nasıl çalıştığını değil, nasıl “nefes aldığını” bildiğinizi kanıtlar.
esxtop ilk bakışta karmaşık bir metrik bombardımanı gibi görünse de; bu rehberdeki sistematik yaklaşımı (CPU > Memory > Storage > Network) izlediğinizde, en kaotik sorunların bile çözülebilir parçalara ayrıldığını göreceksiniz.
Unutmayın; vCenter size sistemin “ateşi olduğunu” söyler, ESXTOP ise “enfeksiyonun hangi hücrede olduğunu” gösterir. Bu görünürlük, MTTR (Mean-Time-To-Resolution) sürenizi saatlerden dakikalara indirir. Modern izleme platformları (Aria Operations vb.) trend analizi ve kapasite planlama için vazgeçilmezdir; ancak “yangın anında” ihtiyacınız olan en hızlı müdahale aracı her zaman esxtop olacaktır.
Happy Troubleshooting! 🚀
Kaynaklar ve Referanslar
VMware Resmi Dokümantasyonu
- Interpreting esxtop Statistics – VMware KB 1008205
- Performance Best Practices for VMware vSphere 8.0
- vSphere Monitoring and Performance Guide
- Understanding CPU Ready Time – VMware KB 1017926
- Understanding Memory Reclamation – VMware KB 1018206
Topluluk Kaynakları
Son yazılar için;
Anthropic Academy Nedir? Ücretsiz Claude AI Eğitimleri ve Sertifika Programları
Claude Code’un Yaratıcısından: Profesyonel Kullanım Rehberi
Sistem Güncellemeleri: Canberk’in 2025 Yama Notları
HPE Synergy 12000 Frame Kapsamlı Teknik İnceleme