
Bu haftanın içerik konusunu yine yapay zeka dünyasından seçtim. Bugün MiniMax M2.7’ye yakından bakacağız.
Yapay zeka dünyasında uzun süredir konuşulan ama çoğu zaman pazarlama cümlesi gibi duran bir fikir var: Bir model, kendi geliştirme sürecine gerçekten katkı vermeye başladığında ne olur?
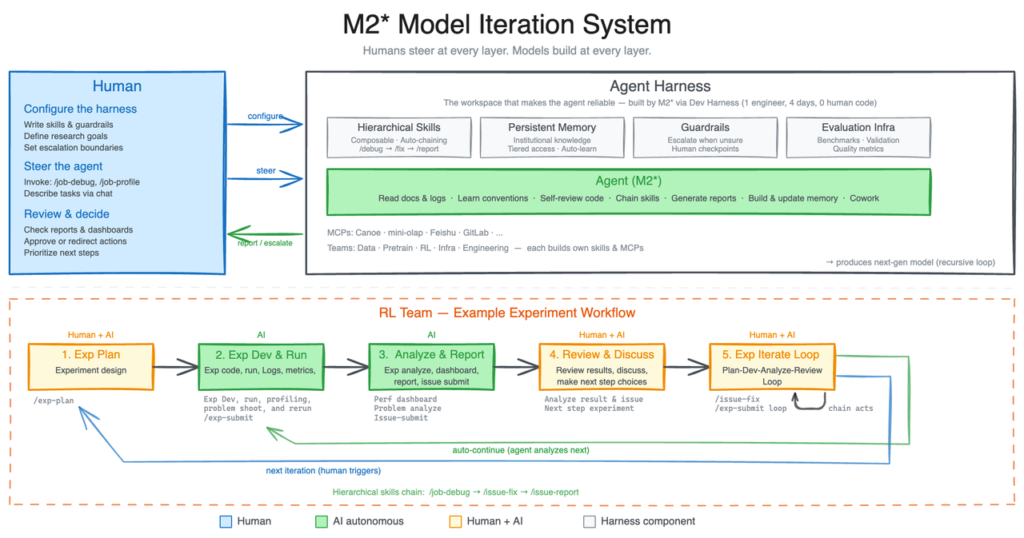
MiniMax, M2.7 ile tam olarak bu sorunun etrafında konumlanıyor. Şirketin 18 Mart 2026 tarihli duyurusu, klasik bir “yeni model çıktı, benchmark da şöyle” metninden biraz farklı. Burada anlatılan şey yalnızca daha iyi bir LLM değil; araştırma ajanları, scaffold optimizasyonu, çok turlu agent harness yapıları ve modelin kendi geliştirme döngüsünde aktif rol alması.
İşin en ilginç tarafı da bu anlatının tamamen boş olmaması. M2.7 gerçekten de güçlü bir coding/agent modeli gibi görünüyor. Ama aynı zamanda “self-evolution” söyleminin nerede gerçek teknik ilerleme, nerede iyi paketlenmiş pazarlama olduğunu ayırmak gerekiyor.
Bu yazıda MiniMax M2.7’yi biraz kurcalayacağız: teknik mimarisi ne söylüyor, resmi benchmark’larda nerede duruyor, Claude ve ChatGPT gibi araçlara karşı hangi senaryoda anlamlı bir alternatif haline geliyor, hangi noktada hâlâ temkinli olmak gerekiyor?
MiniMax Kimdir?
MiniMax, Çin merkezli bir yapay zeka şirketi. Son dönemde yalnızca metin modelleriyle değil; ses, video, müzik ve agent tarafındaki ürünleriyle de görünür hale geldi. M2 serisi ise şirketin özellikle coding ve agent kullanım senaryolarına odaklanan metin modeli hattı olarak öne çıkıyor.
M2.7’yi önemli yapan şey, sıfırdan yepyeni bir kategoriyi açması değil. Asıl mesele, MiniMax’in bunu “agent-first, coding-heavy, production-minded” bir konumla sunması. Yani amaç, her konuda en güçlü genel model olmak değil; daha çok gerçek iş akışlarında yüksek verim vermek.
Bu yüzden M2.7’ye bakarken onu salt bir “ChatGPT rakibi” gibi okumak eksik kalır. Daha doğru çerçeve şu: Bu model, yoğun agent işlerinde ve çok turlu üretkenlik akışlarında ciddi şekilde optimize edilmiş bir çalışma motoru olabilir mi?
M2.7’nin Asıl İddiası Ne?
MiniMax’in resmi anlatısında M2.7’nin merkezinde iki başlık var:
- Recursive self-improvement / self-evolution fikri
- Agent harness ve karmaşık görev yürütme becerisi
İlk başlık kulağa biraz fazla büyük gelebilir. Haklı olarak da öyle. Çünkü “kendini geliştiren model” ifadesi, kolayca abartıya açık bir alan. Ancak MiniMax burada tamamen sihirli bir bilinç sıçramasından söz etmiyor. Daha somut bir mekanizma tarif ediyor:
- başarısız görevleri analiz eden,
- hangi değişikliklerin fayda sağlayacağını planlayan,
- scaffold veya görev akışında düzenleme yapan,
- yeni değerlendirmeleri çalıştıran,
- çıkan sonuca göre iyileştirmeyi tutan ya da geri alan
bir döngüden bahsediyor.
Kısacası mesele “model kendi kendine AGI oldu” değil. Mesele daha çok şu: model, araştırma ve optimizasyon hattında anlamlı bir yardımcı işgücü haline geliyor.
Bence M2.7’nin önemli tarafı tam burada başlıyor. Çünkü frontier model yarışında fark yaratan şey artık sadece daha çok parametre ya da daha iyi benchmark ezberi değil; hangi modelin gerçek dünyadaki üretim akışlarında ne kadar otonom çalışabildiği.
Self-Evolution: Gerçekten Yeni Bir Şey mi?
Dürüst olmak gerekirse, hem evet hem hayır.
Hayır; çünkü AI destekli değerlendirme, model-generated feedback, otomatik hata analizi, RLAIF benzeri döngüler ve scaffold tuning gibi fikirler tamamen yeni değil. Büyük laboratuvarların uzun süredir bu doğrultuda çalıştığını biliyoruz.
Evet; çünkü MiniMax bunu yalnızca araştırma notu gibi bırakmıyor, doğrudan ürün konumlandırmasının parçası yapıyor. Yani “bizim modelimiz bu süreçlere yardım ediyor” demek yerine, M2.7’nin kendi geliştirme akışlarında belirgin görevler üstlendiğini vurguluyor.
Duyurudaki en dikkat çekici detaylardan biri, modelin kendi scaffold’unu optimize etmek üzere 100’den fazla iterasyonluk bir döngüde çalıştırılmış olması. Burada iddia edilen sonuç, iç değerlendirmelerde anlamlı performans kazanımı elde edilmesi.
Bu nokta önemli ama burada frene de basmak lazım.
“Self-evolution” ifadesini, kendi başına yeni bir bilimsel paradigma gibi okumak doğru değil. Daha doğru okuma şu olur: MiniMax, agent tabanlı optimizasyonu ürün mesajının merkezine yerleştirmiş ve bunu ölçülebilir örneklerle desteklemeye çalışmış. Bu ciddi bir sinyal. Ama yine de kontrollü okunması gereken bir sinyal.
Mimari Tarafta Ne Görüyoruz?
MiniMax dokümantasyonuna göre M2.7, Sparse Mixture-of-Experts (MoE) mimarisine dayanıyor. Toplam parametre sayısı yaklaşık 230 milyar, ancak model her token işleminde bunun yalnızca ~10 milyarını aktive ediyor. Bu tasarım çıkarım maliyetlerini doğrudan aşağı çekiyor; ve M2.7’nin agresif fiyatlandırmasının arkasındaki teknik temel tam da bu.
Context window tarafında ise model 204.800 token ile geliyor. Bu sınır, toplam giriş ve çıkış penceresi olarak tanımlanıyor. Standard model için yaklaşık 60 token/saniye, M2.7-highspeed için ise yaklaşık 100 token/saniye çıkış hızı belirtiliyor.
Bu veriler iki şeyi açıkça gösteriyor:
- Model uzun görevleri çevirebilecek kadar geniş bir pencereye sahip.
- Şirket, yalnızca kaliteye değil hız ve throughput tarafına da bilinçli oynuyor.
Bu da zaten M2.7’nin neden klasik “genel sohbet modeli” gibi değil, daha çok iş yapan model gibi konumlandığını açıklıyor.
Bir diğer kritik nokta ise şu: M2.7, MiniMax ekosistemindeki daha geniş multimodal ürün ailesinin parçası olsa da, pratik kullanımda onu öne çıkaran şey doğrudan görüntü/video gösterisi değil; text-first, agent-heavy productivity yaklaşımı.
Yani bu modelin hikayesi “bakın ne kadar güzel resim anlıyor” değil. Hikâye daha çok şu: uzun görevlerde, araç çağırmalı senaryolarda ve kod/ürün akışlarında ne kadar iş çıkarıyor?
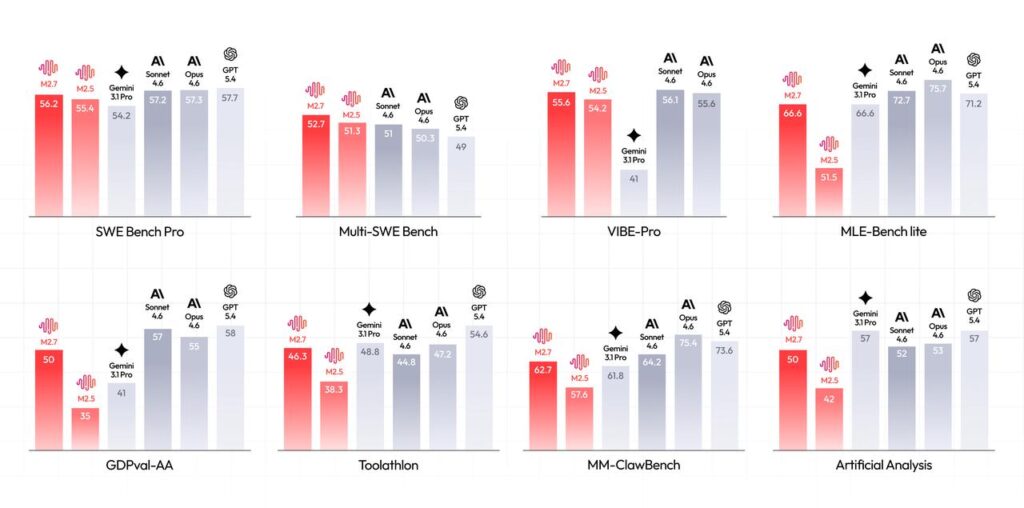
Benchmark’larda Neden Dikkat Çekti?
MiniMax’in resmi duyurusu, M2.7’yi özellikle üç eksende öne çıkarıyor:
1) Yazılım mühendisliği
SWE-Pro tarafında verilen skor, modeli üst sınıf coding modellerine oldukça yakın bir yere koyuyor. Resmi rakam %56,22 ile GPT-5.3-Codex ile eşdeğer bir seviye. Resmi metin, bunun yalnızca tek dosyalık düzenlemelerle sınırlı olmadığını; repo ölçeğinde görev teslimi ve kompleks mühendislik sistemlerini anlama tarafında da modelin iddialı olduğunu söylüyor.
Bu önemli. Çünkü bugün coding modelleri arasındaki fark sadece “kod yazabiliyor mu?” sorusundan çıkmış durumda. Asıl fark yaratan alanlar şunlar:
- büyük repo içinde yön bulma,
- çok adımlı hata ayıklama,
- kısmi başarısızlıklardan toparlanma,
- araç kullanımı,
- terminal ve görev akışıyla uyum.
M2.7’nin güçlü tarafı da tam olarak burada konumlanıyor.
2) Ofis ve profesyonel üretkenlik
MiniMax, GDPval-AA ve benzeri ölçümlerde M2.7’nin ofis üretkenliği tarafında ciddi biçimde güçlendiğini vurguluyor. Buradaki mesaj net: model sadece kod yazmak için değil; Excel, PPT, Word gibi çok turlu düzenleme gerektiren kurumsal akışlarda da daha güvenilir bir teslim kapasitesine oynuyor.
Bu alan genelde geri planda kalıyor ama aslında çok kritik. Çünkü kurumsal kullanım senaryolarında sorun çoğu zaman “şiir yazdırmak” değil; karmaşık talimatları bozmadan, çok adımlı bir işi sonuna kadar götürmek.
3) Makine öğrenimi araştırma akışları
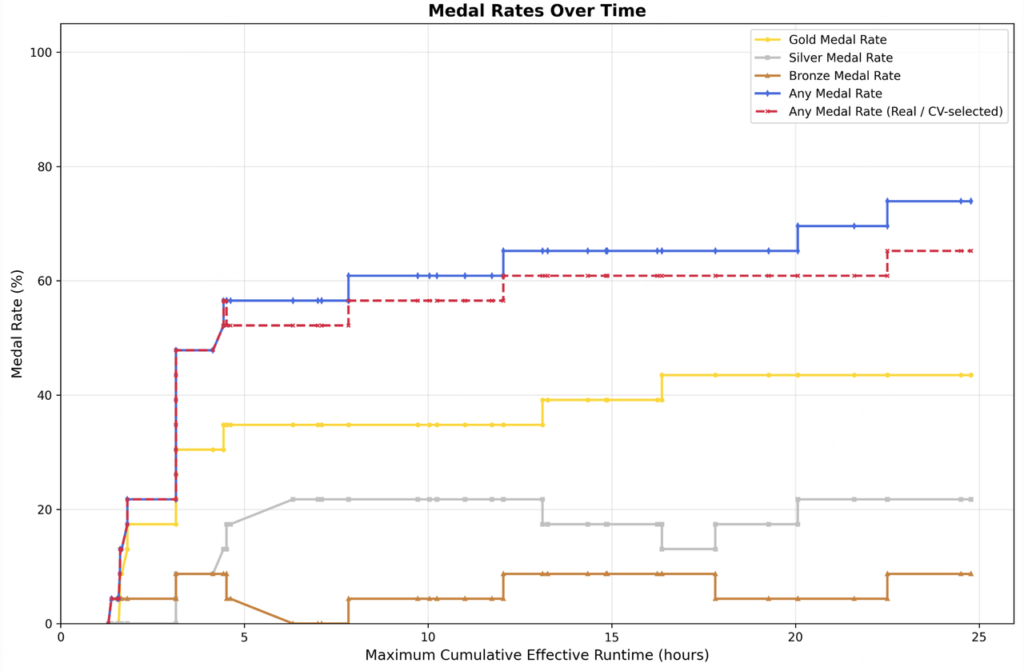
Duyuruda öne çıkarılan bir başka başlık da MLE-Bench Lite performansı. Burada M2.7, üç adet 24 saatlik iteratif deneme sonunda ortalama %66,6 madalya oranı elde etti; en iyi denemede 9 altın, 5 gümüş, 1 bronz. Karşılaştırma için: Claude Opus 4.6 %75,7, GPT-5.4 %71,2, Gemini 3.1 ise M2.7 ile aynı seviyede %66,6. Buradaki esas değer yalnızca yarışma benzeri benchmark başarısı değil. Asıl mesaj şu: model, ML research loop içinde daha uzun süre ayakta kalabiliyor ve bir işi tek adımda değil, iteratif biçimde sürdürebiliyor.
İşte M2.7’nin “self-evolution” anlatısını ciddiye almamız gereken yer burası. Çünkü araştırma workflow’larında anlamlı olmak, klasik benchmark skorundan daha zor bir eşik.
Son olarak tabloya bir de hallüsinasyon tarafından bakmak gerekiyor. Artificial Analysis ölçümüne göre M2.7, %34 hallüsinasyon oranıyla Claude Sonnet 4.6’nın (%46) ve Gemini 3.1 Pro Preview’un (%50) altında kalıyor. Tek başına bu veriyi abartmamak lazım; hallüsinasyon metrikleri ölçüm koşullarına çok duyarlı. Ama üretim ortamında faktüel doğruluk kritikse bu fark göz ardı edilemez.
Peki Claude, ChatGPT ve Gemini Karşısında Nereye Oturuyor?
Burada en doğru yaklaşım şu: M2.7’yi “her şeyi geçen model” gibi anlatmamak.
Bence daha dürüst tablo şöyle:
M2.7’nin güçlü olduğu alanlar
- agent workflow’ları
- coding ve repo düzeyinde görev takibi
- uzun ve çok adımlı üretkenlik işleri
- maliyet hassasiyeti yüksek kullanım senaryoları
- yüksek hacimli batch ve automation iş yükleri
Hâlâ soru işareti taşıyan alanlar
- genel amaçlı en yüksek seviye muhakeme
- multimodal deneyim beklentisi
- çok geniş geliştirici ekosistemi ve araç entegrasyon olgunluğu
- uzun vadeli güven / süreklilik / model politikasının istikrarı
Yani bir kullanıcı olarak “ben tek model seçeyim, her işimi o görsün” diyorsanız, bu noktada Claude, ChatGPT ve Gemini’nin sunduğu daha oturmuş ekosistem avantajı hâlâ çok değerli.
Ama şöyle bir senaryoda M2.7 çok daha ilginç hale geliyor:
“Ben agent iş yükü çalıştırıyorum. Çok sayıda görev döndürüyorum. Kod ve üretkenlik tarafında iyi kalite istiyorum ama maliyetim de kritik.”
İşte bu denklemde MiniMax ciddi şekilde masaya oturuyor.
Fiyatlandırma Tarafı Neden Bu Kadar Önemli?
MiniMax’in güncel API fiyatlandırmasına göre:
| Model | Input ($/1M token) | Output ($/1M token) |
|---|---|---|
| Claude Opus 4.6 | $5,00 | $25,00 |
| GPT-5.4 | $2,50 | $15,00 |
| Gemini 3.1 Pro | $2,00 | $12,00 |
| MiniMax-M2.7 | $0,30 | $1,20 |
| MiniMax-M2.7-highspeed | $0,60 | $2,40 |
Bu tablo, M2.7’yi yalnızca teknik olarak değil, ekonomik olarak da ilginç hale getiriyor.
Çünkü agent tabanlı işlerde maliyet tek seferlik bir mesele değil. Asıl sorun, görevlerin defalarca çalışması, hata vermesi, yeniden denenmesi ve bir orkestrasyon katmanının bunları tekrar tekrar çevirmesi. Tam da bu yüzden düşük birim maliyet, sadece “ucuz model” anlamına gelmiyor; farklı ürün mimarilerini mümkün kılıyor.
Bu da M2.7’nin neden dikkat çektiğini açıklıyor. Frontier’a yakın deneyim vermeye çalışan ama bunu daha agresif fiyatla sunan bir model, özellikle startup’lar ve agent tabanlı ürün geliştiren ekipler için doğrudan karar değiştirici olabilir.
Bir Detay Daha: MiniMax, Claude Code İçinde Kullanımı Özellikle Öneriyor
MiniMax dokümantasyonunda dikkat çeken ilginç bir detay var: M2.7 için hazırlanan kullanım rehberinde doğrudan “Use MiniMax-M2.7 in Claude Code (Recommended)” ifadesi yer alıyor.
Bu küçük gibi görünen detay aslında büyük bir şeyi anlatıyor.
Şirket sadece “bizim modelimiz iyi” demiyor. Aynı zamanda, geliştiricilerin zaten alışık olduğu tooling katmanları içine girmek istiyor. Yani savaş artık yalnızca model kalitesinde değil; hangi model, hangi araç zincirinin içinde daha kolay kullanılabiliyor sorusunda.
Bu açıdan bakınca M2.7, yalnızca benchmark savaşı veren bir model değil; geliştirici alışkanlıklarının içine sızmaya çalışan pragmatik bir hamle.
Zayıf Taraflar ve Soru İşaretleri
M2.7 etkileyici görünüyor. Ama burada birkaç kritik çekinceyi net söylemek lazım.
1) “Self-evolution” anlatısı kolayca abartılabilir
Evet, ortada ilginç bir teknik yaklaşım var. Ama bunu “kendi kendini geliştiren bağımsız zeka” gibi okumak doğru değil. Şu aşamada daha isabetli tanım, insanların kurduğu değerlendirme ve optimizasyon çerçevesi içinde yüksek katkı veren agentic model olur.
2) Ekosistem olgunluğu
Bir modelin benchmark’ta iyi olması başka, geliştirici güveni kazanması başka. OpenAI, Anthropic ve Google tarafında zaman içinde oturmuş kullanım alışkanlıkları, SDK deneyimi, topluluk rehberleri ve entegrasyon pratikleri var. MiniMax bu alanda hızla yükselse de, güven ve benimsenme zaman isteyen bir konu.
3) Ürün politikası
Önceki MiniMax modellerinin açık ağırlık politikasıyla anılması, daha sonra kapalı tarafa kayan ürün stratejisiyle birlikte topluluk tarafında doğal soru işaretleri yaratıyor. Bu da özellikle self-hosting, veri egemenliği ve uzun vadeli platform güveni düşünen ekipler için önemli bir başlık.
4) Her işe aynı derecede uygun değil
M2.7’nin gücü belirli alanlarda yoğunlaşıyor. Bu yüzden onu her senaryo için evrensel bir “en iyi model” gibi sunmak doğru olmaz. Asıl değeri, doğru iş yükünde çok verimli çalışmasında.
MiniMax M2.7 Neden Gerçekten Önemli?
MiniMax M2.7’yi önemli yapan şey, yalnızca iyi bir benchmark tablosu değil.
Asıl önemli taraf şu:
- Modeli, gerçek iş akışlarında çalışan bir agent motoru gibi konumlandırıyor.
- Kendi geliştirme döngüsüne model katkısını, ürün anlatısının merkezine taşıyor.
- Bunu yaparken fiyat/performans tarafında ciddi şekilde agresif davranıyor.
- Frontier sınıfına “en pahalı olan kazanır” mantığı dışında da yaklaşılabileceğini gösteriyor.
Benim çıkarımım şu:
MiniMax M2.7, 2026’nın en önemli “fiyat/performans + agent workflow” hamlelerinden biri.
Bu model, Claude ya da ChatGPT’nin yerini her senaryoda alacak diye okumamak lazım. Ama özellikle coding, automation, araştırma akışları ve çok turlu üretkenlik senaryolarında, “daha düşük maliyetle ne kadar ileri gidebiliriz?” sorusuna çok güçlü bir cevap veriyor.
Daha da önemlisi, M2.7 bize yeni dönemin yönünü gösteriyor:
Gelecekte yarış sadece daha iyi cevap veren modeller arasında olmayacak. Kendi geliştirme süreçlerine daha fazla katılan, daha uzun süre ayakta kalan ve daha fazla işi insan müdahalesi olmadan tamamlayabilen modeller asıl farkı yaratacak.
M2.7 belki bu hikâyenin son noktası değil. Ama ilk ciddi sinyallerinden biri olabilir.
Sıkça Sorulan Sorular
MiniMax M2.7 nedir?
MiniMax M2.7, MiniMax tarafından 18 Mart 2026’da duyurulan yeni nesil büyük dil modelidir. Özellikle coding, agent task’leri ve üretkenlik odaklı kullanım senaryolarında konumlanır.
MiniMax M2.7 neden bu kadar konuşuluyor?
Çünkü sadece benchmark skorlarıyla değil, modelin kendi geliştirme akışlarına katkı verdiği “self-evolution” anlatısıyla öne çıkıyor. Buna ek olarak fiyatlandırması da oldukça agresif.
MiniMax M2.7 multimodal mı?
MiniMax’in genel ürün ailesi multimodal olsa da, M2.7’nin öne çıkan kullanım hikâyesi text-first agent ve coding senaryoları etrafında kuruluyor.
MiniMax M2.7 Claude ve ChatGPT’nin alternatifi mi?
Belirli kullanım senaryolarında evet. Özellikle maliyet hassasiyeti yüksek agent ve coding iş yüklerinde güçlü bir alternatif olabilir. Ancak genel amaçlı kullanımda ekosistem, araç olgunluğu ve kullanım alışkanlıkları tarafında Claude, ChatGPT ve Gemini hâlâ çok güçlü konumda.
MiniMax M2.7’nin en güçlü tarafı ne?
Bence en güçlü tarafı, benchmark skoru ile maliyeti aynı anda masaya koyabilmesi. Yani “iyi model” olmanın ötesinde, “ürünleştirilebilir model” hissi vermesi.
Kaynaklar
- MiniMax M2.7 resmi duyurusu: https://www.minimax.io/news/minimax-m27-en
- MiniMax model sayfası: https://www.minimax.io/models/text/m27
- MiniMax API model/dokümantasyon sayfaları: https://platform.minimax.io/docs/
- MiniMax fiyatlandırma: https://platform.minimax.io/docs/guides/pricing-paygo
- MiniMax M2.7 for AI Coding Tools: https://platform.minimax.io/docs/guides/text-ai-coding-tools
İlgili Yazılar: