
İki adet Dell Pro Max with GB10, bu hafta evdeki homelab’ıma yerleşti. Grace Blackwell Superchip, 128 GB birleşik bellek, 200 Gbps QSFP ile birbirine bağlı. Tek cihaz Qwen3.6-35B-A3B FP8’de saniyede 49,7 token üretiyor. İkisi konuşunca NCCL bandwidth 23,36 GB/s’ye çıkıyor. Serinin giriş yazısı: mimari, kutu açılışı, kurulum ve yol haritası.
128 GB birleşik bellek, masaüstü güç zarfında yaklaşık 1 PFLOP FP4 throughput ve iki cihazı tek havuza dönüştüren 200 Gbps QSFP interconnect; hepsi 15×15 cm boyutunda bir kutuda. Dell Pro Max with GB10 ile NVIDIA, uzun süredir ya datacenter yatırımı ya da cloud faturası arasında sıkışıp kalmış on-prem AI hikayesine yeni bir seçenek ekliyor. Ortada kalan grup için artık küçük modellerle yetinmek veya düşük token hızlarına katlanmak zorunda değiliz.
Bu yazı, iki adet Dell Pro Max with GB10 ile başladığım serinin giriş bölümü. Önce cihazın mimarisine bakıyoruz ve neden sıradan bir iş istasyonundan farklı olduğunu anlıyoruz. Sonra kutuları açıp iki cihazı da masaya yerleştiriyoruz, DGX OS’u kurup ağa alıyoruz. Yazının sonunda önümüzdeki haftalarda yayımlanacak serinin yol haritasını çiziyoruz. Cihazlar elimde, cluster ayakta, ilk ölçümler yapıldı; gerçek rakamlar serinin ilerleyen bölümlerinde bölüm bölüm gelecek.
Grace Blackwell Superchip: Mimari Temeller
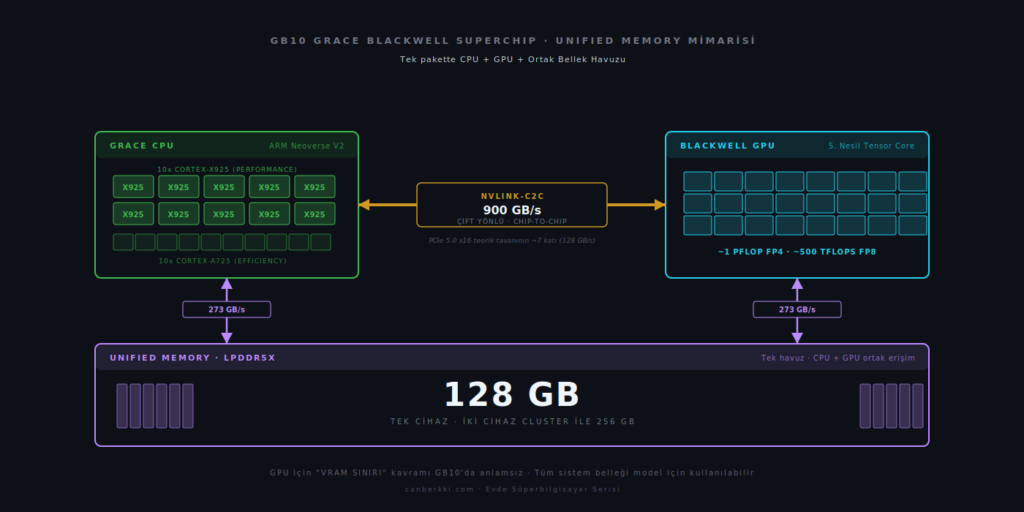
GB10 ismi iki bileşenden oluşuyor: Grace CPU ve Blackwell GPU. Bu iki ayrı silikon parçası, NVLink-C2C (Chip-to-Chip) bağlantısıyla tek bir pakette birleştirilmiş durumda ve aralarındaki bağlantı çift yönlü 900 GB/s bant genişliği sunuyor. Karşılaştırma için PCIe 5.0 x16 teorik 128 GB/s veriyor; yani fark yaklaşık yedi kat.
Bu sayı soyut bir mimari detay değil. LLM inference senaryosunda tokenizer, prefetch ve model loading işlemleri CPU tarafında çalışır ve geleneksel discrete GPU sistemlerinde bu veri PCIe üzerinden GPU’ya taşınırken ciddi bir darboğaz oluşur. GB10’da NVLink-C2C, bu darboğazı büyük ölçüde ortadan kaldırıyor.
Grace CPU tarafı
Grace, NVIDIA’nın ARM Neoverse V2 temelli CPU tasarımı ve GB10 için 20 çekirdekli bir konfigürasyonla geliyor: 10 yüksek performans (Cortex-X925) ve 10 verimlilik (Cortex-A725) çekirdeği. Datacenter segmentindeki Grace Hopper ve Grace-Grace sistemlerinde aynı aile CPU’lar kullanılıyor, GB10 ise bunun masaüstü güç zarfına optimize edilmiş versiyonu.
LLM inference açısından Grace’in rolü sessiz ama kritik. Tokenization, embedding lookup, sampling ve scheduler işleri CPU’da çalışır ve bu işleri yeterince hızlı yapamazsanız pahalı GPU boşta kalır.
Blackwell GPU tarafı
GB10’daki Blackwell GPU, datacenter B100/B200’ün küçük kardeşi sayılır. 280W sistem güç zarfına sığacak şekilde ölçeklendirilmiş ve B100’ün HBM3e belleği yerine LPDDR5X ile çalışıyor. Ama mimarinin temel avantajları burada da mevcut: 5. nesil Tensor Core’lar, FP4 ve FP8 native desteği, geliştirilmiş Transformer Engine.
Pratik karşılığı: ~1 PFLOP FP4, ~500 TFLOPS FP8 AI throughput. Bu rakam, özellikle FP8 native destekleyen güncel modellerde (Qwen3.5, Qwen3.6, DeepSeek V3, Llama 3.3) anlamlı bir fark yaratıyor. FP4 native destek ise NVFP4 quantization ile 400B+ modelleri iki GB10 üzerinde çalıştırılabilir hale getiriyor.
Unified Memory: Asıl fark yaratan kısım
Geleneksel GPU sistemlerinde bellek iki ayrı havuzda yaşar: sistem RAM’i ve GPU VRAM’i. Büyük modeller için bu bir kâbus; model önce CPU RAM’ine yükleniyor, sonra PCIe üzerinden GPU VRAM’ine kopyalanıyor ve VRAM’i aşan modeller hiç yüklenemiyor.
GB10’da bu ayrım yok. 128 GB LPDDR5X bellek, hem Grace CPU hem Blackwell GPU tarafından doğrudan erişilebilen tek bir havuz olarak duruyor ve GPU için “VRAM sınırı” kavramı GB10’da anlamsız hale geliyor. Sistemin tüm belleği model için kullanılabilir durumda.
Bu mimari, 70B parametreli bir modelin FP16 ağırlıklarla (~140 GB) yüklenmesine tek cihazda yetişmese de, Q4_K_M quantization ile 70B modeli 40-42 GB civarında tutar. Yani 128 GB’ın üçte birinden azı; geri kalan alanda ya birden fazla model instance’ı, ya aynı modelin fine-tuning’i, ya da büyük context penceresi için ayıracak yer kalıyor.
Teknik Özellikler
| Özellik | Değer |
|---|---|
| AI Performance | ~1 PFLOP FP4 / ~500 TFLOPS FP8 |
| Unified Memory | 128 GB LPDDR5X |
| Memory Bandwidth | 273 GB/s (CPU + GPU ortak erişim) |
| NVLink-C2C | 900 GB/s (CPU ↔ GPU) |
| Network | 2x 200 Gbps QSFP (ConnectX-7 SmartNIC) + 1x 10 GbE RJ-45 |
| I/O | 4x USB-C 20Gbps, 1x HDMI |
| CPU | 20-core Grace (10x X925 + 10x A725) |
| OS | DGX OS 7.2 (Ubuntu 24.04 LTS tabanlı) |
| Güç Zarfı | 280W max, ~40-60W idle |
| Form Factor | Masaüstü (15 x 15 x 5 cm, Mac Mini’den birazcık daha kompakt) |
Sayılar kâğıt üzerinde güzel duruyor ama asıl soru şu: bu spesifikasyonların gerçek dünyadaki karşılığı ne? Serinin geri kalanı tam olarak bu soruya cevap veriyor.
Kutuları Açmak
İki cihazı da aynı gün teslim aldım. Dell’in kurumsal ambalajları çoğunlukla sadedir; GB10 de bu geleneğe uyuyor. Kutuyu kaldırdığınızda hafif şaşırıyorsunuz. 280W’lık bir AI iş istasyonu beklerken elinizde 2-3 kg’lık bir paket oluyor.

Kutudan çıkanlar:
- Cihazın kendisi. Mat siyah alüminyum gövde, üst kapak hafif kavisli.
- Güç adaptörü ve kablo. Masaüstü formuna göre iri bir power brick. 280W için beklenen seviye.
- Hızlı başlangıç kılavuzu. Türkçe dahil birkaç dilde.
- Dell garanti ve yasal belgeler.

Kutudan çıkmayan kritik kalem: QSFP kablosu. İki cihazı cluster olarak çalıştıracaksanız 200 Gbps QSFP Direct Attach Copper (DAC) kablosu ayrıca temin etmeniz gerekiyor ve NVIDIA MCP1650 serisi veya NADDOD uyumlu alternatifler 15-45 USD aralığında bulunuyor. Yan yana iki cihaz için 0,5 m yeterli olduğu için siparişi cihazla aynı anda verin, yoksa iki cihaz masada QSFP portları boş bekler.
Cihazı elinize aldığınızda küçük boyutuna rağmen sağlam bir gövde hissediliyor ve alüminyum şasi 280W’lık yükü termal olarak absorbe edecek kütleye sahip. Ön yüz tamamen sade; petek desenli havalandırma ızgarası dışında hiçbir şey yok, tüm iş arka panelde.
Haftasonu eğlencesi başlıyor… Dell Pro Max with GB10 🔥 pic.twitter.com/LywDHNadqI
— canberk (@canberkys) April 18, 2026
Arka panel düzeni:
- 2x 200 Gbps QSFP: (ConnectX-7 SmartNIC üzerinde). Cluster bağlantısı için.
- 1x 10 GbE RJ-45: Yönetim ağı için. Standart 1 GbE değil, çoğu modern anakarttan daha hızlı bir ağ portu.
- 4x USB-C 20Gbps. Hepsi USB4/Thunderbolt sınıfı. Harici NVMe disk, monitör, dock, çevre birimleri için.
- HDMI. İlk kurulumda KVM için.
- Güç girişi + açma/kapama düğmesi.

Panel iki farklı mesaj veriyor. Birincisi cihazın ağ tarafının agresif tasarlanmış olması: cluster için 2x 200 Gbps QSFP ve yönetim için standart üstü 10 GbE sayesinde model indirme, container image transferi, dataset yüklemesi gibi operasyonlar tek cihazda bile belirgin şekilde hızlanıyor. İkincisi ise cihazın bilinçli olarak modern bir iş istasyonu pozisyonunda konumlanması; USB-A portu yok, hepsi USB-C 20Gbps.
ConnectX-7 kartı üzerindeki iki QSFP portunun her biri 200 Gbps ve cluster performansı bu portların nasıl kullanıldığına doğrudan bağlı. Serinin 5. ve 6. bölümlerinde bu portlar üzerinden kurduğum RoCE (RDMA over Converged Ethernet) tabanlı cluster’ı ve NCCL benchmark sonuçlarını detaylı işleyeceğim.
Masa Üstü Kurulumu
İki cihazı çalışma masama yan yana, bitişik şekilde yerleştirdim. Aralarında QSFP DAC kablosu kısa bir kavisle dolaşıyor. İki cihazın toplam boyutu 13 inç iPad’den küçük.


Fiziksel kurulum tamamlandıktan sonra ilk açılış için KVM tercih ettim. Cihazın headless kurulum desteği var ama ilk açılışta sistemi gözlemleyebilmek için monitör bağlamak pragmatik bir seçim oluyor. Güç düğmesine bastıktan sonra ilk POST ekranı yaklaşık 25-30 saniyede geldi; önce NVIDIA logosu, ardından Grub menüsü ve DGX OS’un karşılama ekranı.
DGX OS 7.2, Ubuntu 24.04 LTS tabanlı ve üzerinde NVIDIA’nın AI stack’i (CUDA, cuDNN, NCCL, containerd, nvidia-container-toolkit) önceden yapılandırılmış durumda. Ubuntu deneyimi olan herkes için tanıdık bir ortam; büyük bir sürpriz yok.
İlk yapılandırma sihirbazı standart Ubuntu kurulumu gibi işliyor: dil, saat dilimi, klavye, yönetici hesabı. Kayda değer tek fark NVIDIA EULA ve DGX OS telemetri ayarları; kurumsal ortamda kullanacaksanız telemetri tercihini gözden geçirmek isteyebilirsiniz.
İlk Konfigürasyon: Ağ, Firmware, nvidia-smi
İlk yapılandırma bitince iki iş kaldı.
Ağ. İlk açılışta DHCP bırakıyorum çünkü cluster konfigürasyonunda iki cihazın statik IP ve sabit hostname almaları gerekecek, ama bu iş sonraki bölümün konusu. Şimdilik internet çıkışı ve SSH erişimi için DHCP yeterli.
Firmware ve sistem güncellemeleri. DGX OS açılışta otomatik güncelleme kontrolü yapıyor ve iki cihazda da BMC firmware’i ile birkaç paket güncellemesi geldi. Süreç toplamda 20-25 dakika sürüyor ve bir-iki kere yeniden başlatma gerekiyor.
Firmware güncellemesini asla bölmeyin. Güç kesintisi ya da erken kapatma cihazı kullanılamaz hale getirebilir. “Güncelleme tamamlandı” mesajı gelene kadar bekleyin.
Güncellemeler bittikten sonra ilk sağlık ve CUDA kontrolleri :
nvidia-smi
nvcc --versionÇıktıda GPU NVIDIA GB10 Grace Blackwell adıyla listeleniyor, 128 GB unified memory doğru raporlanıyor ve sürücü versiyonu güncel. nvcc --version ise CUDA 13 gösteriyor. İlk aşamada doğrulamak istediğim bundan ibaretti: her iki cihazda sistem ayakta, sürücüler doğru ve bellek havuzu beklendiği gibi.
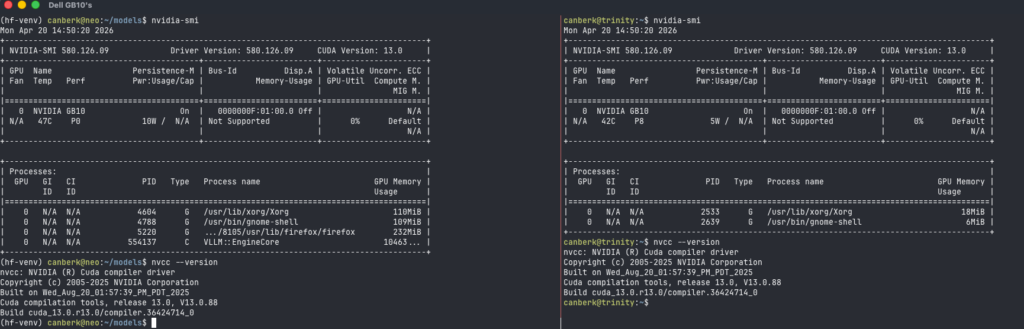
İkinci cihazda aynı süreci tekrarladım; tek fark hostname ve IP oldu. Yan yana duran iki cihaza verdiğim isimler neo ve trinity; cluster hostname’leri çalıştıkça yüzlerce kez yazıldığı için akılda kalır, hızlı yazılır ve birbirine karışmayan isimler işi kolaylaştırıyor.
Bu aşamadan sonra klavye, fare ve monitör artık gereksiz hale geliyor. Kalan tüm iş, yani kurulumun geri kalanı, cluster yapılandırması, model deployment ve benchmark işleri Mac’imden SSH üzerinden yapılacak; bu geçiş serinin 2. bölümünün konusu.
İlk Rakamlar
Bu bir giriş yazısı, tam benchmark ilerleyen bölümlerde geliyor. Ama serinin niyeti ve ölçeği hakkında fikir vermek için iki kritik sayı paylaşmak gerekiyor:
| Metrik | Değer | Bağlam |
|---|---|---|
| Tek cihaz sustained decode | 49,7 tok/s | Qwen3.6-35B-A3B-FP8, vLLM 0.17.1, FlashAttention |
| Cluster NCCL bus bandwidth | 23,36 GB/s | 2x GB10, 200G QSFP DAC, tuning sonrası |
Qwen3.6-35B-A3B-FP8 modelinde tek cihaz sustained decode 49,7 tok/s. Alibaba bu modeli (tek cihazda çalıştırdığım model) 16 Nisan’da yayınladı. vLLM 0.17.1 container’ı üzerinde, FP8 native, FlashAttention açık.
İki cihaz arası NCCL all-reduce bus bandwidth 23,36 GB/s. 200 Gbps QSFP DAC üzerinden, tuning sonrası ölçüm; tek yönlü teorik 25 GB/s tavanının yaklaşık %93’ü. Bidirectional all-reduce pattern’ı için bu oran, driver güncellemeleri öncesinde alınabilecek pratik tavana çok yakın. Tuning süreci (THP, MTU, IRQ affinity, NCCL parametreleri) toplam +%7,4 kazanım sağladı.
Bu sayıların her biri kendi başına bir bölümü dolduracak; prefill hızı, TTFT, paralel kullanıcı scaling’i, güç tüketimi-performans oranı, tek ve çift cihaz karşılaştırması gibi başlıklar her biri kendi metodolojisiyle ayrı ayrı gelecek. Gerçek hikaye hem ham sayılarda hem de bu sayılara giden yolda saklı.
Muadili Cihazlar ile Karşılaştırması
Dell Pro Max with GB10’u değerlendirmenin en doğru yolu benzer kullanım amacındaki alternatiflerle karşılaştırmaktan geçiyor.
| Platform | AI Bellek | AI Performans | Pratik LLM Sınırı | Fiyat (yaklaşık) |
|---|---|---|---|---|
| Dell Pro Max with GB10 | 128 GB unified | ~1 PFLOP FP4 | 70B Q4-FP8 | ~$4,000 / ~230K TL |
| Apple M4 Ultra Mac Studio | 192 GB unified | ~800 TOPS (ANE) | 70B Q4-Q6 | ~$4,500+ |
| NVIDIA RTX 5090 WS | 32 GB GDDR7 (ayrı) | ~3,352 TOPS | 14-34B FP16, 70B kısıtlı | ~$5,000+ |
| GMKtec EVO-X2 (AMD 395+) | 128 GB unified | ~126 TOPS (XDNA) | 70B Q4, ROCm/Vulkan | ~$2,000 |
| 2x Dell Pro Max with GB10 | 256 GB unified | ~2 PFLOP FP4 | 400B+ MoE, Q4/NVFP4 | ~$8,000 / ~460K TL |
İki kritik karşılaştırma öne çıkıyor.
Apple M4 Ultra vs GB10. M4 Ultra daha fazla birleşik bellek sunuyor (192 GB vs 128 GB), ama iki cihazla bakarsanız GB10 çifti 256 GB’a çıkıyor. Asıl ayrışma mimari farkta: Blackwell FP4/FP8 native, MLX ve Apple Metal’in henüz bu precision’larda tam eşleşmediği bir alanda oyuna giriyor. CUDA ekosistemi (vLLM, TensorRT, NIM, Triton) GB10’da sorunsuz çalışıyor; Apple’da karşılıkları var ama ekosistem daha dar.
RTX 5090 vs GB10. RTX 5090 ham TOPS’ta GB10’u yaklaşık 3,3x geçiyor, ama 32 GB GDDR7 VRAM 70B FP16 model için yetersiz kalıyor ve quantization veya multi-GPU şart oluyor. GB10 felsefesi farklı: raw throughput değil, erişilebilir model boyutu önceliği. Küçük modellerde RTX 5090 kazanırken 70B+ sınıfında GB10 oyuna giriyor.
Dell Pro Max with GB10: Seri Yol Haritası
Aldığım notlara, haftasonu çektiğim screenshot’lara ve kafamdaki yapılacaklar listesine bakınca serinin 11 bölüm dolayında olacağını görüyorum. Yol ilerledikçe bazı başlıkları birleştirebilir veya ayrı bölümlere bölebilirim. Her makaleyi kendi başına değer taşıyacak şekilde yazıyorum, takip etmek için önceki tüm bölümleri okumanız gerekmeyecek.
| # | Bölüm | Kapsam |
|---|---|---|
| 01 ● | İlk Bakış, Kurulum ve Cluster Planı (bu yazı) | Mimari, unboxing, DGX OS kurulumu, yol haritası |
| 02 | macOS’tan Headless Yönetim ve İlk Model | Statik IP, SSH key-based auth, for-loop ile çift cihaz yönetimi, Ollama kurulumu, Open WebUI, ilk sohbet |
| 03 | vLLM’e Geçiş: FP8 Inference ve İlk Benchmark | vLLM 0.17 container, CUDA graphs, Qwen3.6-35B ölçümleri |
| 04 | İki Cihazı Birleştirmek: QSFP, Hostname, SSH Mesh | netplan, passwordless key-based SSH, cluster temel yapısı |
| 05 | OpenMPI + NCCL: Cluster’ın Dili | nccl-tests, all-reduce, baseline benchmark |
| 06 | Cluster Tuning: +%7,4 Nereden Geldi? | THP, MTU, IRQ affinity, NCCL parametreleri |
| 07 | Enerji ve Metrik Dashboard’u | GPU utilization, güç, bellek, canlı görselleştirme |
| 08 | Tensor Parallel ile 70B+ Modeller | TP=2, Llama 3.3 70B, Qwen3.5-397B-A17B denemeleri |
| 09 | Production: OpenAI-Uyumlu API + Entegrasyon | Webex bot, n8n workflow, IDE entegrasyonu |
| 10 | TCO Analizi ve Retrospektif | 3 yıllık maliyet, break-even, kapanış notları |
Kimler İçin, Kimler İçin Değil
Her platform bir trade-off yapar ve GB10’un güçlü olduğu ile zorlandığı yerler oldukça net.
Güçlü olduğu senaryolar. Veri mahremiyeti kritik sektörler (bankacılık, sağlık, hukuk, kamu); yoğun API kullanıcıları (günlük milyonlarca token); 70B+ sınıfı model çalıştırmak isteyen araştırmacılar ve multi-node cluster deneyimi kazanmak isteyen homelab kullanıcıları için ideal bir seçim.
Zorlandığı senaryolar. Sadece 7-13B sınıfı modellerle çalışan kullanıcılar için RTX 5090 ham hız avantajıyla daha iyi bir seçim olabilir. macOS-first iş akışı olanlar için Mac Studio M4 Ultra daha bütünlüklü bir çözüm; ayda birkaç kez kullanacak hafif kullanıcı için ise maliyet fazla yüksek ve cloud abonelikleri daha rasyonel kalıyor.
Dell Pro Max with GB10, CUDA ekosisteminin tam entegre bir şekilde masaüstüne indiği ilk noktalardan biri. 128 GB erişilebilir bellek, 280W güç zarfı ve iki cihazla 400B+ modellere uzanan bir kapasite; hepsi sıradan bir evde, sıradan bir prizde. Mimari iddiası güçlü duruyor ve sayılar serinin geri kalanında konuşacak.
Serinin 2. bölümünde klavye, fare ve monitörü kaldırıyoruz. Her iki cihaza statik IP, hostname ve SSH key-based authentication kurup macOS’tan ssh neo ile ssh trinity komutlarıyla tek terminalden iki cihazı birden yönetebildiğim headless bir setup çıkıyor ortaya. Sonraki bölümde ise ilk model kuruluyor ve Open WebUI üzerinden tarayıcıda çalışan kişisel bir AI’ya kavuşuyoruz.
Sıradaki Bölüm → Bölüm 02: macOS’tan Headless Yönetim ve İlk Model
İlgili Yazılar: